在阅读《人工科学》第五章时,西蒙在书中提到这样一个比喻:
在干草堆中搜索一根缝衣针所需要的时间取决于针的分布密度,而与草堆有多大无关。
这句话比较反常识。
按常规理解,搜索一根缝衣针的时间,自然与缝衣针所处的场域大小相关:场域大,搜索时间越长,反之愈短 —— 这是一个合理的推断,为什么西蒙判断与场域大小无关?
我开始通过ChatGPT寻找答案,首先是对ChatGPT的身份进行定位:

GPT随后给到我对第五章的整体理解,并表示这一章的内容「非常丰富」:
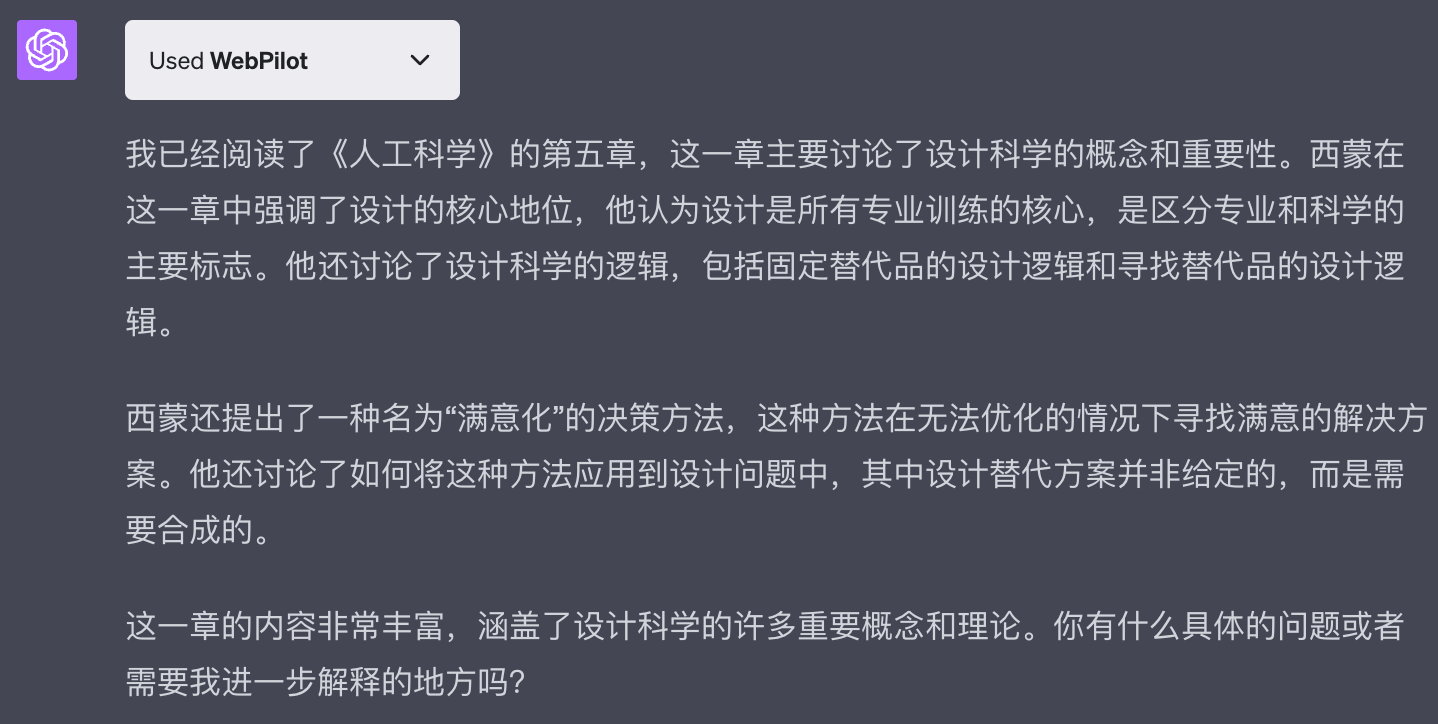
我找到《人工科学》原文,让GPT联系上下文进行解答:

GPT解释如下:
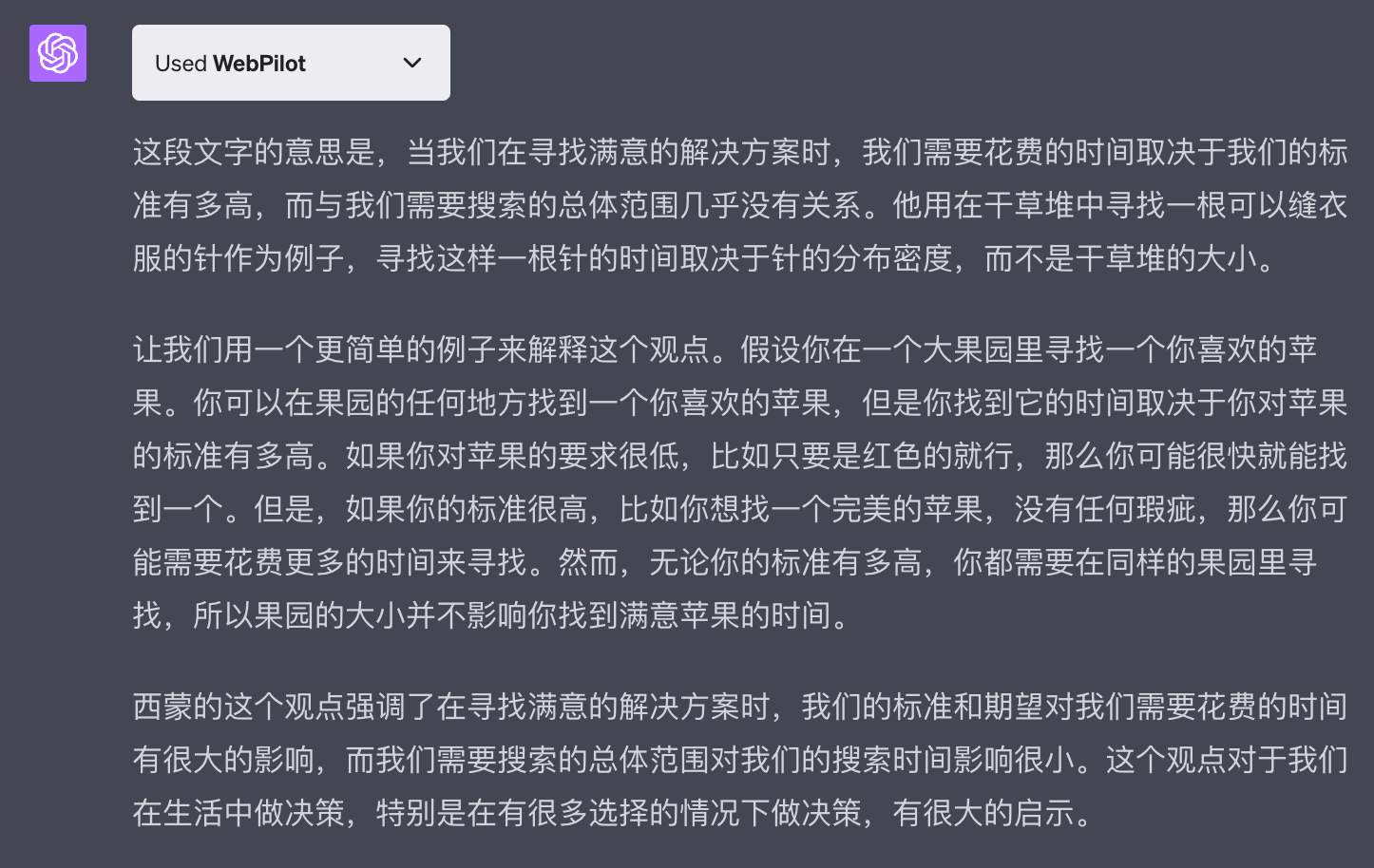
GPT举了一个在果园寻找苹果的简单案例,可以简单拆解一下:
| 比喻类别 | 比喻指向 | 比喻含义 |
|---|---|---|
| 比喻 | 苹果 | 不同人寻找苹果时对所寻找苹果的要求有高低之分 |
| 比喻 | 果园 | 果园的大小对寻找苹果所花的时间长短无关 |
| 源头 | 缝衣针 | 不同人寻找缝衣针时对所寻找缝衣针的要求有高低之分 |
| 源头 | 干草堆 | 干草堆的大小对寻找缝衣针所花的时间长短无关 |
这样的解释看起来是合理的:如果我们对苹果的要求低,自然花的时间短。但西蒙在原文中提到的针的「分布密度」,而这一点GPT在上述回答中并没有提到,所以我进一步追问它:

GPT继续用一个简单的例子向我解析分布密度的概念:

看得出来这次GPT将焦点集中在了「分布密度」上,但我发现似乎GPT在仅仅针对「分布密度」这个概念进行封闭解释。因为西蒙在原文中提到的是「一根针」,而一根针何来「分布密度」之说?
所以我想到GPT可能遗忘了概念的前后文(这是GPT的一个现存bug),所以我特别让他重复阅读第五章,根据上下文回答:

GPT开始重读第五章并作出了回答:
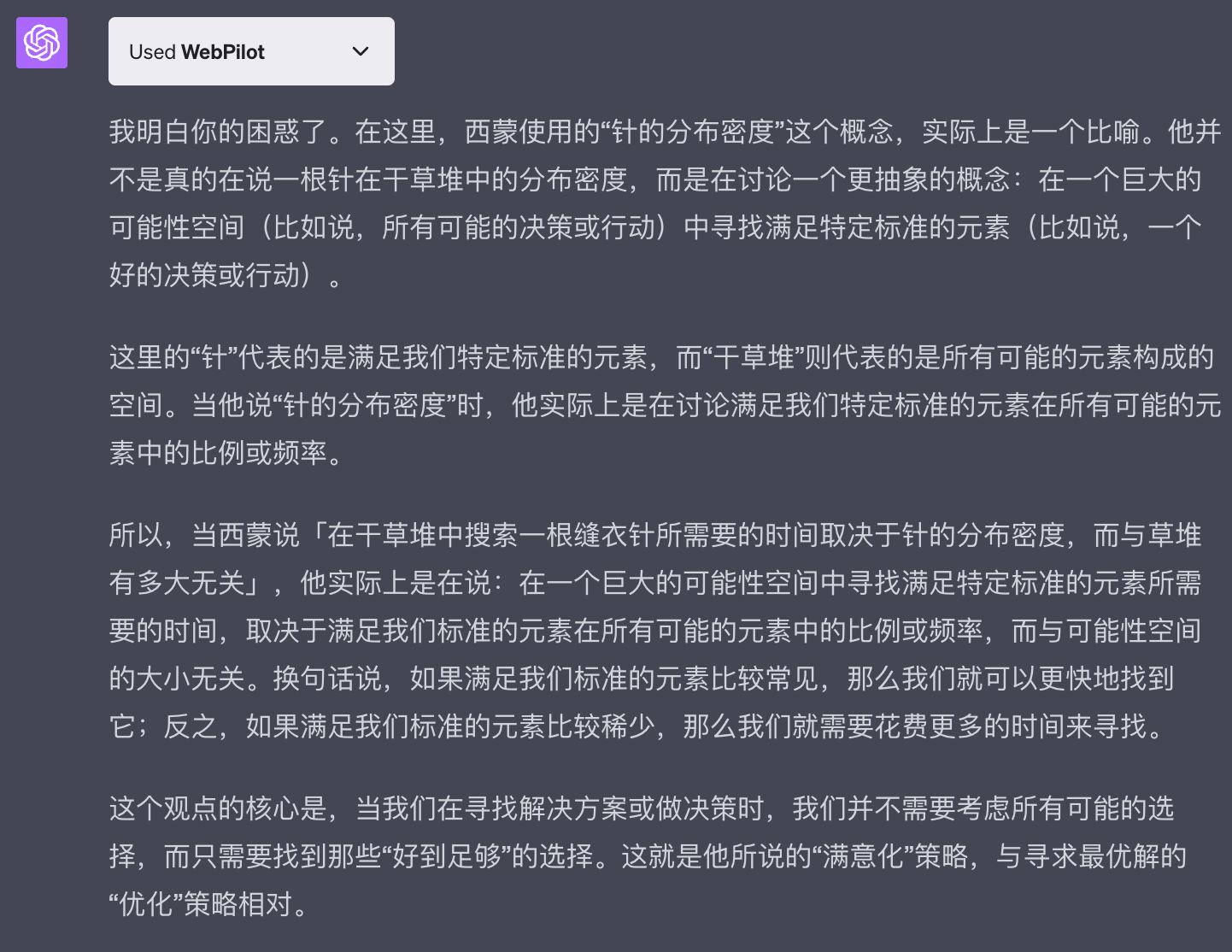
GPT在这里给到了一个关键理解点:
西蒙提到的「在干草堆中搜索一根缝衣针所需要的时间取决于针的分布密度,而与草堆有多大无关」这句话,并不是真的在讨论一根针在草堆中的分布密度,而是在讨论一个更抽象的概念:在一个巨大的可能性空间(比如说,所有可能的决策或行动)中寻找满足特定标准的元素(比如说,好的决策或行动)。
换句话说,我之前对于「一根针何来分布密度之说」的疑问,其实是通向了咬文嚼字的理解偏差,而西蒙想表达的含义其实是一种指代:
| 隐喻元素 | 具体含义 |
|---|---|
| 缝衣针 | 满足我们特定标准的元素 |
| 干草堆 | 所有可能的元素构成的空间 |
| 针的分布密度 | 满足我们特定标准的元素在所有可能的元素中的比例或频率 |
可以看到,GPT的这个回答终于触及到了这个比喻句的核心!它进一步解析到:
如果满足我们标准的元素比较常见,那么我们就可以更快地找到它;
反之,如果满足我们标准的元素比较稀少,那么我们就需要花费更多的时间来寻找。
将上述理解代入「缝衣针」的原话就能得出:如果缝衣针比较常见,我们就能用更短时时间寻找到它,反之则要花费更多的时间寻找缝衣针。
而这里的「常见」就是「满足特定标准」:
- 某决策或行动的特定标准越低 → 寻找到该决策或行动所花的时间就越短。
- 某决策或行动的特定标准越高 → 寻找到该决策或行动所花的时间就越长。
我进一步提出疑问:有哪些原因导致了满足特定标准的差异?换句话说,特定标准为什么会产生差异?
我开始尝试深入解析GPT的这个理解:
在干草堆中搜索一根缝衣针所需要的时间取决于搜索缝衣针的人对「缝衣针」这个概念的理解、目的,以及搜索缝衣针的人自身所拥有的认知程度、他所处的具体情境条件等,这些因素的交错融合最终决定了搜索缝衣针的人搜索缝衣针的时间长短,而与草堆有多大无关。
这里我提到的「理解」、「目的」、「认知」、「情境」来源于我对行为分析课程的理解,影响一个人行为的核心元素包含动机、认知、人格、叙事、情境等。按照行为分析观点,决定一个缝衣针搜索者搜索缝衣针的行为的,也必然包含搜索者的这些隐含条件,而正是这些隐含条件导致了他们搜索行为的差异。
GPT对我的理解回复如下:
你的理解是正确的,但我想稍微调整一下你的表述,以便更准确地反映西蒙的观点:
|
|
这里的关键点是,我们在寻找解决方案或做决策时,我们并不需要考虑所有可能的选择,而只需要找到那些“好到足够”的选择。这就是他所说的“满意化”策略,与寻求最优解的“优化”策略相对。
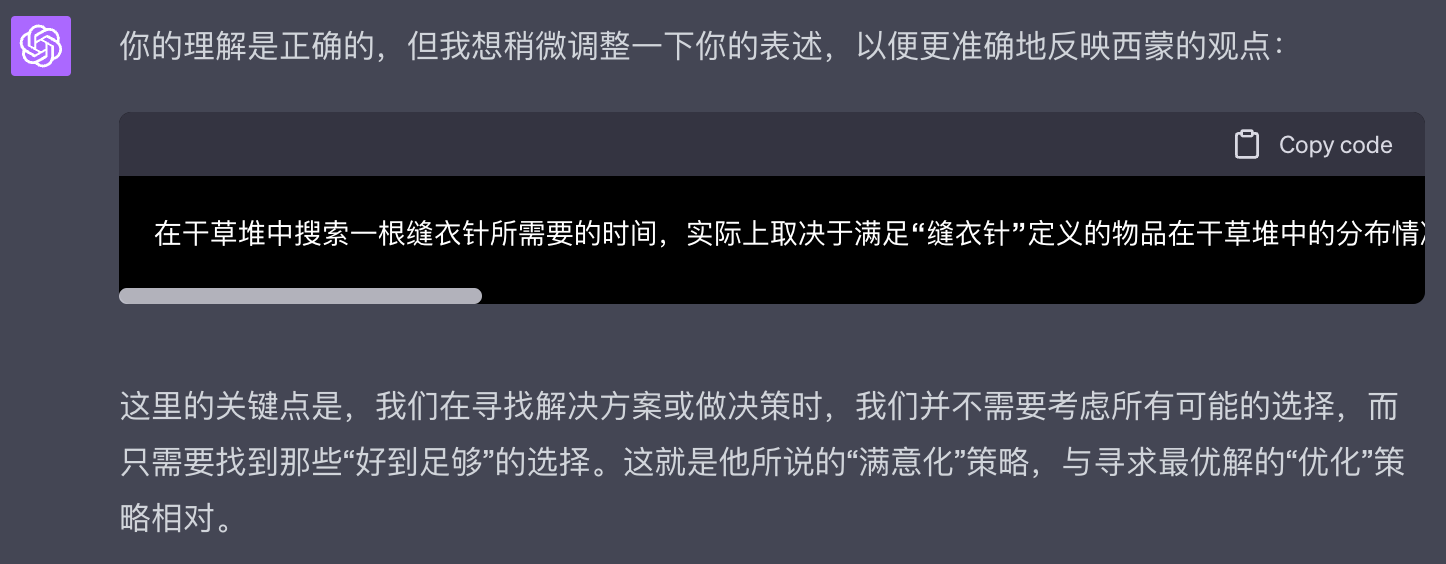
通过GPT的回答可以看到它更加强调「分布情况」和「满意化策略」两点。那么我开始自问自答:
Q:这个「分布情况」到底是如何形成的?
A:这里的「分布情况」取决于搜索者自己的认知。
如何但这个理解用更简单的方式说明?
联想到GPT能采用案例解析的方式,我尝试通过自己的思考来解析这个「分布情况」的差异:
在搜索缝衣针之前,搜索者的大脑中已经形成了对「缝衣针」的认知(这种认知取决于搜索者对「缝衣针」这个概念的理解、搜索者的搜索目的,以及搜索者自身的认知程度和他所处的具体情境条件等因素),所以不同的搜索者对「缝衣针」的认知是存在差异的,并不是完全一致的。这就造成了搜索者在搜索时对「缝衣针」的标准定位差异,而这种差异,就会自动关联搜索者的搜索行为。
试举例:
现在有两个缝衣针搜索者,都接收到了要从干草堆搜索缝衣针的要求,但两者又有区别:
搜索者A:
对「缝衣针」要求一般(比如就想用它来戳一下手),那么A见到比较细且硬的干草时,就会觉得这个「干草」就相当于缝衣针,能够满足自己「戳手」的需求,而他发现满足这种「戳手」的「缝衣针」随处可见,所以A很快就搜索到了自己想要的「缝衣针」,然后停止了搜索。
搜索者B:
对「缝衣针」的标准定位非常细致(比如他认为缝衣针的长度必须为3.2毫米,直径为0.12毫米,硬度为600维氏硬度值),那么在搜索者眼中,干草堆中符合这个标准的缝衣针的概率就比较低了,所以B需要花更多时间去寻找这根缝衣针。
这里A与B搜索到各自的缝衣针的时间差异,本质上取决于A和B对干草堆中满足自己的对「缝衣针」认知的匹配程度(即「满意度」)的高低,而不是干草堆有多大。
简单图示如下:
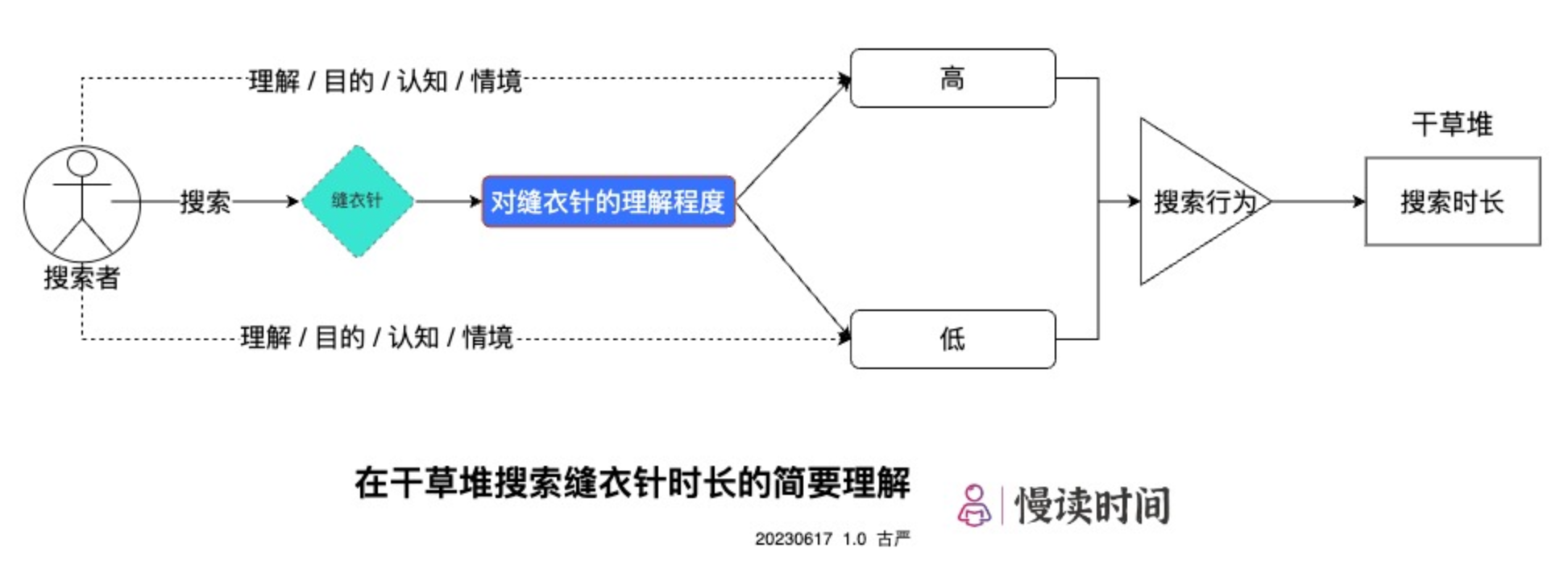
回到文初提到的常规理解「搜索一根缝衣针的时间,自然与缝衣针所处的场域大小相关:场域大,搜索时间越长,反之愈短」,它的理解偏差出现在何处呢?
认为「在干草堆中搜索一根缝衣针所需要的时间取决于草堆有多大」观点的默认假设,是没有考虑到不同搜索者对缝衣针的认知差异,认为所有搜索者对「缝衣针」的都是统一高度的认知标准,进而导致所有搜索者都是采用相同的方法去搜索缝衣针。
一样的标准 + 一样的搜索方法,那么最后决定搜索到缝衣针的时间长短,就是干草堆的大小了。
但事实正好相反,认知是行动的必要前提条件。
所以,西蒙通过「在干草堆中搜索一根缝衣针所需要的时间取决于针的分布密度,而与草堆有多大无关」这个抽象比喻提醒我们,每个人在寻找解决方案或做决策时,要明白每个人对解决问题标准的理解是不一样的,所以就会导致他们并不需要考虑所有可能的选择项,而只需要找到那些「足够满足自己标准」的选择,这就是西蒙的「满意化」策略,与寻求最优解的「优化」策略相对。
我整合上述理解让GPT来评估:

GPT评估如下:

至此,西蒙「在干草堆中搜索一根缝衣针所需要的时间取决于针的分布密度,而与草堆有多大无关」总计37个字的比喻句,我通过6次询问ChatGPT,最终用2888个字解析理解成功。
Ref:
-
《人工科学》 赫伯特·西蒙
Changelog
20230616 23:43 1.0
20230617 08:51 1.1 增补图示理解